
加密流量分类-实践3: TrafficClassificationPandemonium流量分类项目分析
加密流量分类-实践3: TrafficClassificationPandemonium流量分类项目分析
1 项目简介
该项目是流量预处理与分类验证的一个统一实现,力求使用清晰的项目结构与最少的代码实现预设功能,目前支持的模型只有1dcnn、app-net两种,后续会进行更新。代码已经开源至露露云的github,如果能帮助你,就给鼠鼠点一个star吧!!!
2 项目使用
2.1 流量预处理(pcap->npy)
提取网络数据流量的负载、包长序列、统计(当前版本还未实现)的特征,转为
npy格式进行持久化存储,基于flowcontainer库
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置preprocess的参数,以下是一个示例preprocess: traffic_path: ../traffic_path/android # 原始pcap的路径 datasets: ../datasets/android # 预处理后npy文件的路径 packet_num: 4 # 负载特征参数:流的前4包的负载 byte_num: 256 # 负载特征参数:每个包的前256个字节 ip_length: 128 # 包长特征参数:提取流前128个包长序列 threshold: 4 # 阈值:流包长小于4时舍弃 train_size: 0.8 # 训练集所占比例其中对于前
packet_num个包的前byte_num字节可以如图说明
负载、包长均作了舍长补短的操作,以达到特定的格式。
预处理脚本运行:
配置
yaml_path即配置文件路径,然后运行代码entry/1_preprocess_with_flowcontainer.pydef main(): yaml_path = r"../configuration/traffic_classification_configuration.yaml" cfg = setup_config(yaml_path) # 获取 config 文件 pay, seq, label = getPcapIPLength( cfg.preprocess.traffic_path, cfg.preprocess.threshold, cfg.preprocess.ip_length, cfg.preprocess.packet_num, cfg.preprocess.byte_num) split_data(pay,seq,label,cfg.preprocess.train_size,cfg.preprocess.datasets) if __name__=="__main__": main()样本字典补齐:运行完后,得到一个字典输出,将该字典复制到配置文件的
test/label2index下label2index: {'qq': 0, '微信': 1, '淘宝': 2}
2.2 模型训练
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置train/test的参数,以下是一个示例~~~yaml
train:
train_pay: ../TrafficClassificationPandemonium/datasets/android/train/pay_load.npytrain_seq: ../npy_data/test/test/ip_length.npy
train_seq: ../TrafficClassificationPandemonium/datasets/android/train/ip_length.npy
train_sta: None
train_label: ../TrafficClassificationPandemonium/datasets/android/train/label.npy
test_pay: ../TrafficClassificationPandemonium/datasets/android/train/pay_load.npy
test_seq: ../TrafficClassificationPandemonium/datasets/android/train/ip_length.npy
test_sta: None
test_label: ../TrafficClassificationPandemonium/datasets/android/train/label.npy
BATCH_SIZE: 128
epochs: 50 # 训练的轮数
lr: 0.001 # learning rate
model_dir: ../TrafficClassificationPandemonium/checkpoint # 模型保存的文件夹model_name: cnn1d.pth # 模型的名称
model_name: app-net.pth # 模型的名称
test:
evaluate: False # 如果是 True, 则不进行训练, 只进行评测
pretrained: False # 是否有训练好的模型# # # {‘Chat’: 0, ‘Email’: 1, ‘FT’: 2, ‘P2P’: 3, ‘Streaming’: 4, ‘VoIP’: 5, ‘VPN_Chat’: 6, ‘VPN_Email’: 7, ‘VPN_FT’: 8, ‘VPN_P2P’: 9, ‘VPN_Streaming’: 10, ‘VPN_VoIP’: 11}
label2index: {‘qq’: 0, ‘微信’: 1, ‘淘宝’: 2}
confusion_path: ../TrafficClassificationPandemonium/result/confusion/ConfusionMatrix-app-net.png
~~~
运行脚本:运行代码
entry/2_train_test_model.py2.3 模型测试
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置test的参数的evaluate与pretrained为True运行脚本:运行代码
entry/2_train_test_model.py
2.4 结果展现
混淆矩阵的展现
默认在
result/confusion下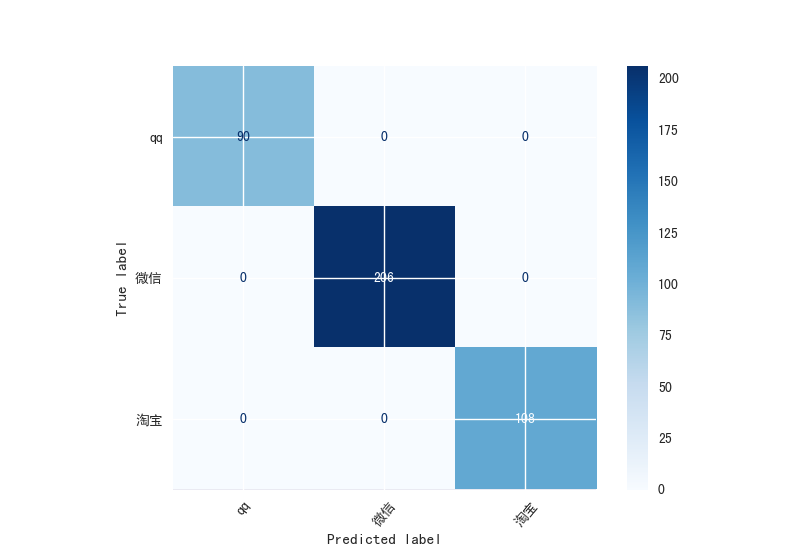
acc、loss曲线的展现训练中或者训练后,使用
tensorboard --logdir /result/tensorboard进行查看
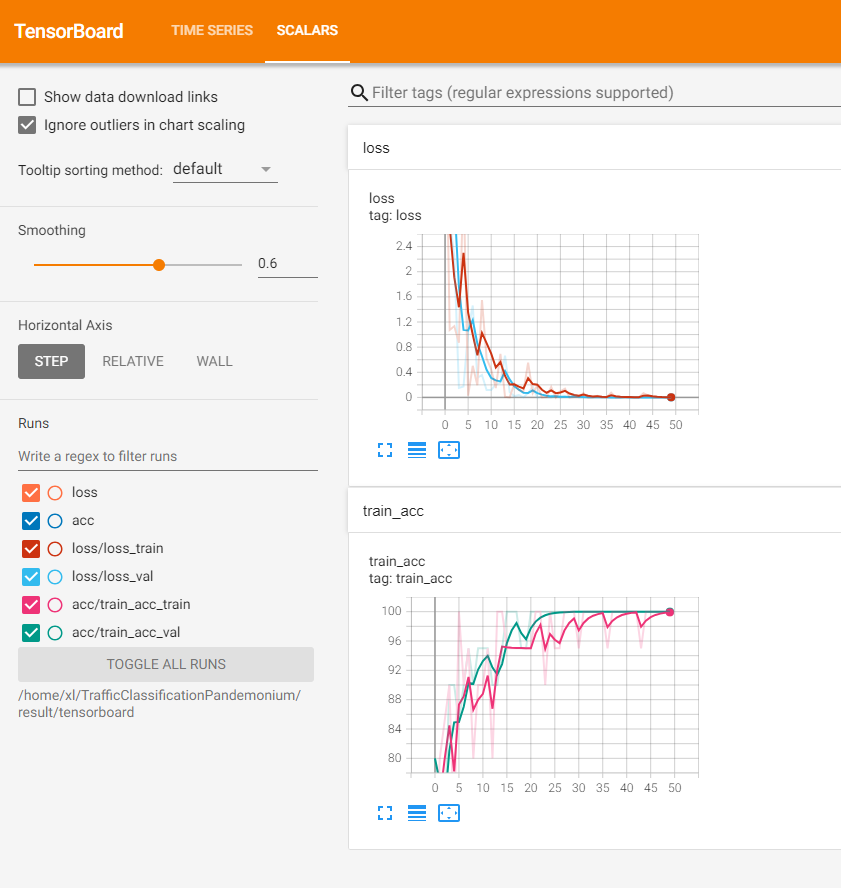
3 项目结构
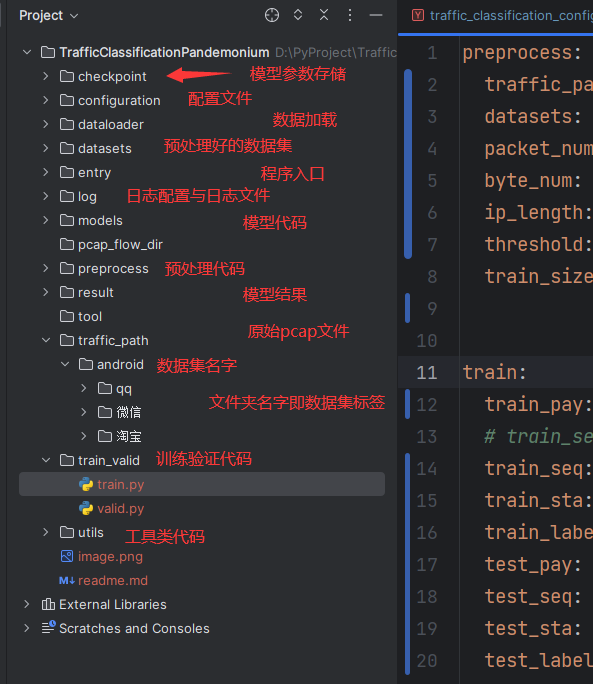
4 扩展性
新增模型:按照
models下面的示例进行新增,模型都有两个返回,一个是分类结果,一个是重构结果(框架为了兼容后续上传的模型)切换模型:在
entry/2_train_test_model.py的20/21行进行导入切换即可,下图为一维卷积与appnet的切换示例