
加密流量分类-实践3: 特征提取
本文于 425 天之前发表,文中内容可能已经过时。
加密流量分类-实践3:特征提取
1、原因
看着博客flowcontainer)的感觉很好,但是有如下缺陷:
处理大文件费内存,关于数据集ISCX2016中的FT类型一个pcap动则就是5个多G,吃不消
设置extension字段提取tcp与udp有效负载时,对于上述的大文件处理特别慢!!!原因是加载所有数据进入内存,但是实际预处理只需要前几个包的有效载荷数据,造成内存大开销!
如果有pcap开始的数据报文不是包含有效载荷的报文,如开始为icmp报文的pcap文件,该库会报错,具体溯源已找到:

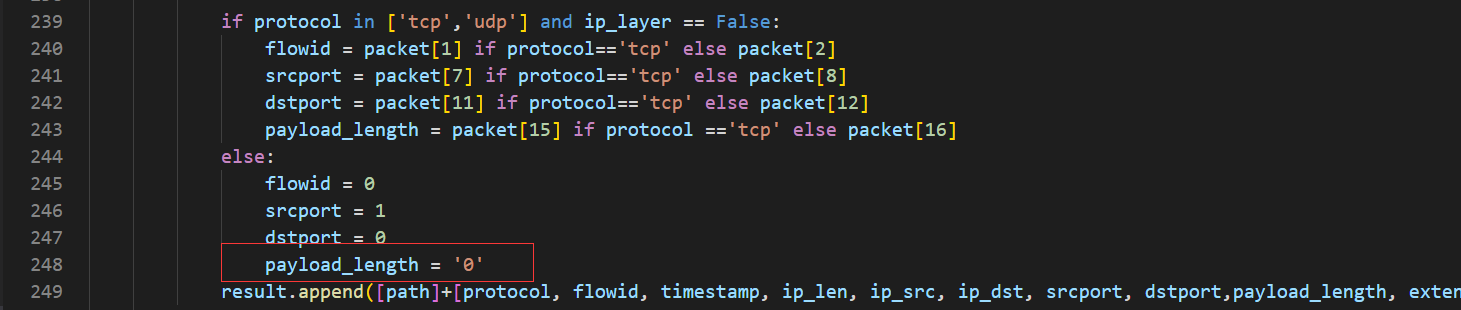
if protocol in ['tcp','udp'] and ip_layer == False: flowid = packet[1] if protocol=='tcp' else packet[2] srcport = packet[7] if protocol=='tcp' else packet[8] dstport = packet[11] if protocol=='tcp' else packet[12] payload_length = packet[15] if protocol =='tcp' else packet[16] else: flowid = 0 srcport = 1 dstport = 0 # 这一行是加上的,如果不加上,payload_length就会为初始化,导致result的appeend失败,从而在流生成的函数里造成对空对象的迭代遍历 payload_length = '0'红色圈圈是加上的代码,加上后就不会出现致命异常
但是依旧是慢!在处理大文件的pcap特别费劲!等个几个小时才读取完!
分流与SplitCap.exe的分流有出入,目前论文主流方法分流是使用SplitCap.exe工具
2、预处理功能
直接上代码:
import binascii
import scapy.all as scapy
import numpy as np
def hex_to_dec(hex_str, target_length):
dec_list = []
for i in range(0, len(hex_str), 2):
dec_list.append(int(hex_str[i:i + 2], 16))
dec_list = pad_or_truncate(dec_list, target_length)
return dec_list
def pad_or_truncate(some_list, target_len):
return some_list[:target_len] + [0] * (target_len - len(some_list))
def pad_or_truncate_seq(some_list, target_len):
return some_list[:target_len] + [0] * (target_len - len(some_list))
# 获取流的长度、方向、到达时间序列
# 一个字节8位,占两个十六进制数字
def get_seq_feature(pcap_path, pack_nums=4, byte_nums=128, seq_length=128, throw=3):
"""
读取分流好的pcap文件,返回它的ip报文长度、到达时间序列与前pack_num个报文的前byte_num字节的负载
"""
packets = scapy.rdpcap(pcap_path)
ip_lengths = []
ip_arrive_time = []
pay_load = []
pay_index = []
if len(packets) <= throw:
return ip_lengths, ip_arrive_time, pay_load,pay_index
dic = {}
pay_num = 0
for i, packet in enumerate(packets):
# 提取包长序列
if i == 0:
dst = packet.src
src = packet.dst
dic = {dst: -1, src: 1}
dst = packet.dst
ip_length = dic[dst] * len(packet)
ip_lengths.append(ip_length)
# 包到达时间提取
ip_arrive_time.append(float(packet.time))
# 提取负载与负载在流中包的序号
if len(packet.payload.payload) != 0:
if pay_num < pack_nums:
pay = packet.payload.payload
# print(type(pay))
# print(pay)
data = (binascii.hexlify(bytes(pay)))
data = hex_to_dec(data, target_length=byte_nums)
pay_load.extend(data)
pay_index.append(i+1)
pay_num += 1
if len(pay_index)<pack_nums:
# 不足
for i in range(pack_nums-len(pay_index)):
data = hex_to_dec([],byte_nums)
pay_load.extend(data)
pay_index.append(-1)
ip_lengths = pad_or_truncate_seq(ip_lengths, seq_length)
ip_arrive_time = pad_or_truncate_seq(ip_arrive_time, seq_length)
return ip_lengths, ip_arrive_time, pay_load, pay_index
首先输入是预处理分流好的pcap文件,使用SplitCap.exe分流即可
- 函数参数解释
pack_nums:提取前几个包的负载 byte_nums:提取包的前几个字节的负载 seq_length:提取流的前几个包的长度(正负表示方向) throw:表示流中的包少于多少个不处理输出:
包长度
包到达时间
包负载
前几个负载包的流中的序号
上述都是短则补0,长则截断
不会有内存不足的问题辣,处理负载也很快,因为不看报头,所以不需要什么匿名ip,mac地址啥的