
加密流量分类-实践2: CNN+LSTM模型训练与测试
本文于 427 天之前发表,文中内容可能已经过时。
加密流量分类torch实践2:CNN+LSTM模型训练与测试
- 代码模板参考:CENTIME:A Direct Comprehensive Traffic Features Extraction for Encrypted Traffic Classification
1、原理
- 一维卷积处理负载数据,处理流前n个包的前m个字节
- Bi-LSTM处理包长序列,取流前seq_length的长度序列
- 模型结构类似于APP-Net
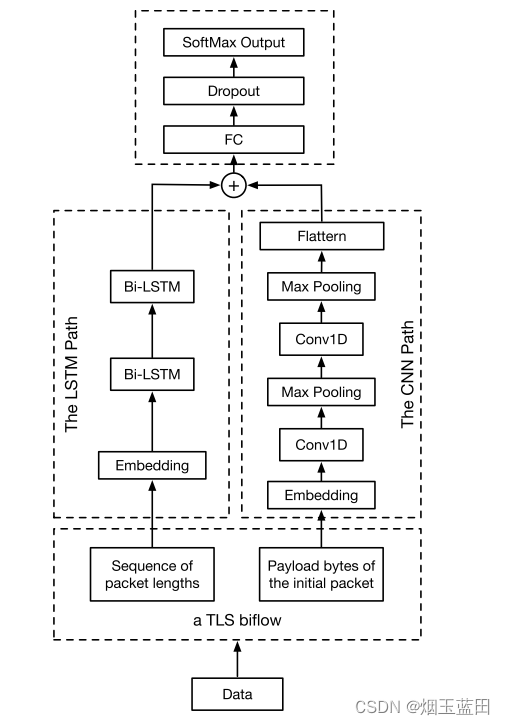
模型代码:
~~~
“””
cnn处理负载
lstm处理包长序列
“””import torch
import torch.nn as nn
class Cnn_Lstm(nn.Module):
def __init__(self,input_size, hidden_size, num_layers,bidirectional,num_classes=12):
super(Cnn_Lstm, self).__init__()
self.bidirectional = bidirectional
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,bidirectional=bidirectional,batch_first=True)
self.fc0 = nn.Linear(hidden_size, num_classes)
self.fc1= nn.Linear(hidden_size*2,num_classes)
self.cnn_feature = nn.Sequential(
nn.Conv1d(kernel_size=25, in_channels=1, out_channels=32, stride=1, padding=12), # (1,1024)->(32,1024)
nn.BatchNorm1d(32), # 加上BN的结果
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3, padding=1), # (32,1024)->(32,342)
nn.Conv1d(kernel_size=25, in_channels=32, out_channels=64, stride=1, padding=12), # (32,342)->(64,342)
nn.BatchNorm1d(64),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3, padding=1), # (64,342)->(64,114)
)
self.cnn_classifier = nn.Sequential(
# 64*114
nn.Flatten(),
nn.Linear(in_features=64*114, out_features=1024), # 784:88*64, 1024:114*64, 4096:456*64
)
self.cnn=nn.Sequential(
self.cnn_feature,
self.cnn_classifier,
)
self.rnn = nn.Sequential(
nn.LSTM(input_size, hidden_size, num_layers, bidirectional=bidirectional, batch_first=True),
)
self.classifier=nn.Sequential(
nn.Linear(in_features=2048,out_features=num_classes),
# nn.Dropout(p=0.7),
# nn.Linear(in_features=1024,out_features=num_classes)
)
def forward(self, x_payload,x_sequence):
x_payload=self.cnn(x_payload)
x_sequence=self.rnn(x_sequence)
x_sequence=x_sequence[0][:, -1, :]
x=torch.cat((x_payload,x_sequence),1)
x=self.classifier(x)
return x
def cnn_rnn(model_path, pretrained=False, **kwargs):
model = Cnn_Lstm(**kwargs)
if pretrained:
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint['state_dict'])
return model
class Cnn(nn.Module):
def __init__(self,input_size, hidden_size, num_layers,bidirectional,num_classes=12):
super(Cnn, self).__init__()
self.bidirectional = bidirectional
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,bidirectional=bidirectional,batch_first=True)
self.fc0 = nn.Linear(hidden_size, num_classes)
self.fc1= nn.Linear(hidden_size*2,num_classes)
self.cnn_feature = nn.Sequential(
nn.Conv1d(kernel_size=25, in_channels=1, out_channels=32, stride=1, padding=12), # (1,1024)->(32,1024)
nn.BatchNorm1d(32), # 加上BN的结果
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3, padding=1), # (32,1024)->(32,342)
nn.Conv1d(kernel_size=25, in_channels=32, out_channels=64, stride=1, padding=12), # (32,342)->(64,342)
nn.BatchNorm1d(64),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3, padding=1), # (64,342)->(64,114)
)
self.cnn_classifier = nn.Sequential(
# 64*114
nn.Flatten(),
nn.Linear(in_features=64*114, out_features=1024), # 784:88*64, 1024:114*64, 4096:456*64
)
self.cnn=nn.Sequential(
self.cnn_feature,
self.cnn_classifier,
)
self.classifier=nn.Sequential(
nn.Linear(in_features=1024,out_features=num_classes),
# nn.Dropout(p=0.7),
# nn.Linear(in_features=1024,out_features=num_classes)
)
def forward(self, x_payload,x_sequence):
x_payload=self.cnn(x_payload)
x=self.classifier(x_payload)
return x_payload
def cnn(model_path, pretrained=False, **kwargs):
model = Cnn(**kwargs)
if pretrained:
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint['state_dict'])
return model
class Lstm(nn.Module):
def __init__(self,input_size, hidden_size, num_layers,bidirectional,num_classes=12):
super(Lstm, self).__init__()
self.bidirectional = bidirectional
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,bidirectional=bidirectional,batch_first=True)
self.fc0 = nn.Linear(hidden_size, num_classes)
self.fc1= nn.Linear(hidden_size*2,num_classes)
self.rnn = nn.Sequential(
nn.LSTM(input_size, hidden_size, num_layers, bidirectional=bidirectional, batch_first=True),
)
self.classifier=nn.Sequential(
nn.Linear(in_features=1024,out_features=num_classes),
# nn.Dropout(p=0.7),
# nn.Linear(in_features=1024,out_features=num_classes)
)
def forward(self, x_payload,x_sequence):
x_sequence=self.rnn(x_sequence)
x_sequence=x_sequence[0][:, -1, :]
x=self.classifier(x_sequence)
return x
def rnn(model_path, pretrained=False, **kwargs):
model = Lstm(**kwargs)
if pretrained:
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint['state_dict'])
return model
## 2、运行
- 在自己的环境下修改路径,包括删除``from sequence_payload.xx import xx``下面的``sequence_payload.``
- 修改配置文件``entry``下面的``traffic_classification.yaml``的路径,与模型参数,名字
- 训练流程代码
from utils.helper import AverageMeter, accuracy
from TrafficLog.setLog import logger
def train_process(train_loader, model, criterion, optimizer, epoch, device, print_freq):
“””训练一个 epoch 的流程
Args:
train_loader (dataloader): [description]
model ([type]): [description]
criterion ([type]): [description]
optimizer ([type]): [description]
epoch (int): 当前所在的 epoch
device (torch.device): 是否使用 gpu
print_freq ([type]): [description]
"""
losses = AverageMeter() # 在一个 train loader 中的 loss 变化
top1 = AverageMeter() # 记录在一个 train loader 中的 accuracy 变化
model.train() # 切换为训练模型
for i, (pcap, seq,target) in enumerate(train_loader):
pcap = pcap.reshape(-1,1,1024)
seq = seq.reshape(-1,64,1)
pcap = pcap.to(device)
seq = seq.to(device)
target = target.to(device)
output = model(pcap,seq) # 得到模型预测结果
loss = criterion(output, target) # 计算 loss
prec1 = accuracy(output.data, target)
losses.update(loss.item(), pcap.size(0))
top1.update(prec1[0].item(), pcap.size(0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % print_freq == 0:
logger.info('Epoch: [{0}][{1}/{2}], Loss {loss.val:.4f} ({loss.avg:.4f}), Prec@1 {top1.val:.3f} ({top1.avg:.3f})'.format(
epoch, i, len(train_loader), loss=losses, top1=top1))
return losses.val,top1.val
- 验证流程代码:
-
## 2.1 数据预处理
原理:
- 使用flowcontainer包提取含有tcp或者udp负载的包,提取负载与ip数据包序列长度<br/>
使用:
- 将原始pcap文件放在``traffic_data``下
- 格式:
|---traffic_data
|---bilibili
|--- xx.pcap
|--- xxx.pcap
|---qq
|--- xx.pcap
|--- xxx.pcap
|--- 今日头条
|--- xx.pcap
|--- xxx.pcap
~~~
- 运行
entry/preprocess.py,完成后复制控制台输出的label2index,粘贴到traffic_classification.yaml/test/traffic_classification.yaml - 得到处理好的
npy_data2.2 训练
打开
entry/train.py,注释或者取消注释40、41、42行,选择cnn、lstm、cnn+lstm进行训练,记得改配置文件的model_name可以打开tensorboard查看loss与acc曲线
- loss:
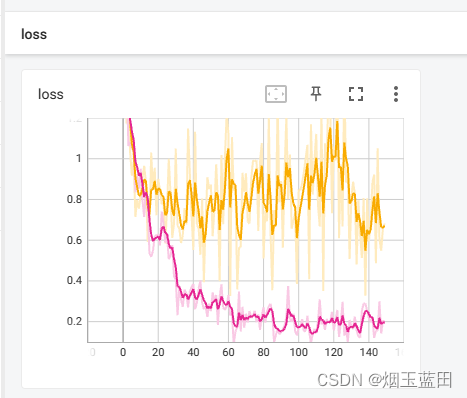
- loss:
- acc:
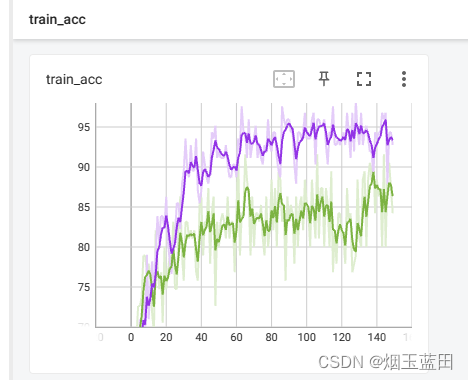
> 两图为lstm处理序列数据的tensorboard示例
2.3 测试
- 修改
traffic_classification.yaml/test/evaluate为True,打开entry/train.py运行,得到评估结果
/evaluate为True,打开entry/train.py``运行,得到评估结果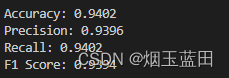
项目地址:lulu-cloud