
加密流量分类-论文10: Global-Aware Prototypical Network for Few-Shot Encrypted Traffic Classification
本文于 545 天之前发表,文中内容可能已经过时。
0、摘要
现在大部分对于小样本学习的方法都是基于度量(metric learning)解决,但是这些方法只考虑到了流量的局部信息,故对最终的分类性能有一定影响
本文提出的GP-Net,考虑负载序列的两个字节之间的关系,利用字节之中的关系聚合流量输入的全局信息
少样本学习是元学习的在监督学习领域的应用,可以参考link](https://zhuanlan.zhihu.com/p/156830039))
1、概念介绍
1.1 基于metric的少样本学习的方法
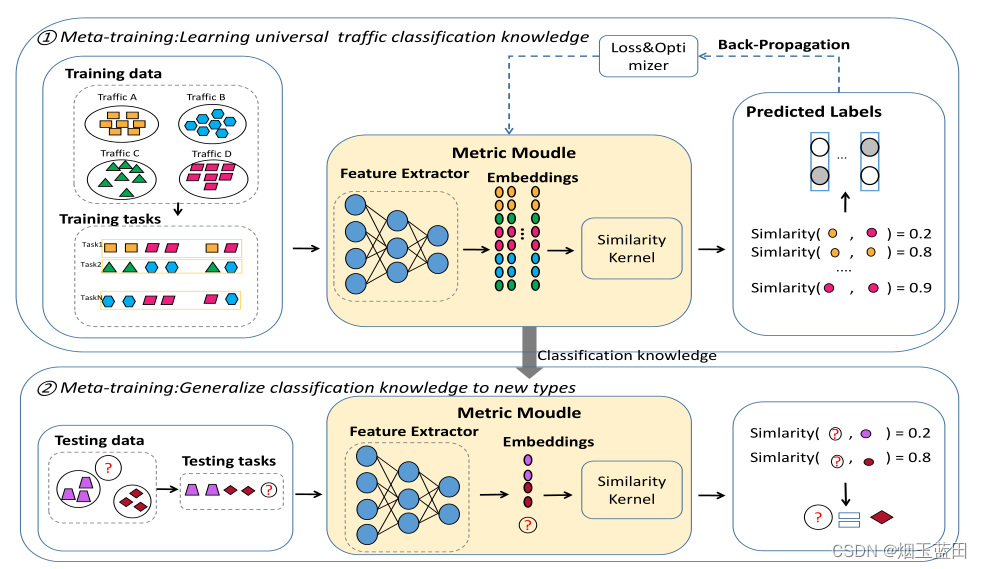
- 过去使用一维卷积神经网络作为编码器解码器提取流量特征的方法,如RBRN)因为卷积核大小的限制,难以提取整个流量的全局信息,因此导致后续计算相似度时,不够精确。
1.4 文章核心观点引入
论文模型优势:在新流量类型样本不足的情况下学习更好的表示方法
四大模块:
流量归一化:将原始流量(输入是流量的有效载荷信息)转为图片
全局感知表示:基于自注意力的思想,并且对负载序列中字节位置信息进行建模,克服自注意力机制中的位置不可知的缺陷,这样就能聚合流量的全局信息.
所谓全局感知,其实就是引入了自注意力机制而已
嵌入生成器:卷积操作,因为前面的全局感知,使得这里的卷积不同于以前论文方法的卷积,全局而不局限
计算相似度模块:与以前方法类似。
通篇下来就是全局两个字
2、初步知识
2.1 元学习概念

元学习概念:与传统的机器学习不同,元学习的基本单元是一个任务而不是一个训练示例。元学习的主要目标是从元训练任务中获取通用的元知识,并将其用于只需少量样本的元测试任务的快速学习。如上图:训练任务与测试任务是不相关的,用不同颜色与形状表示出来,元学习期待从完成元任务中学习到的知识能很好地迁移到待试验数据上。
2.2 问题定义
假定两个流量数据集,都是有标签的,定义为:
意味着Dtr中有C个类别的流量,并且每一种类的流量都有一定的样本,但是,在Dtest中,样本数量非常少,并且类别都是Dtr中没有的。
将训练集与测试集中的任务定义为:
每一个元素代表一个任务,是二元分类,如上图,都由支持集(support set)与查询集(query set)组成,叫法这么叫而已,其实就是训练集与验证集。
支持集与查询集的形成遵循N-way、K-shot原则,即N个流量类型,每个类型抽k个样本。这样在测试任务中,即使测试任务的支持集很小,但是在元学习的表现下,仍然有不错的泛化性。
3 GP-Net
3.1 概览
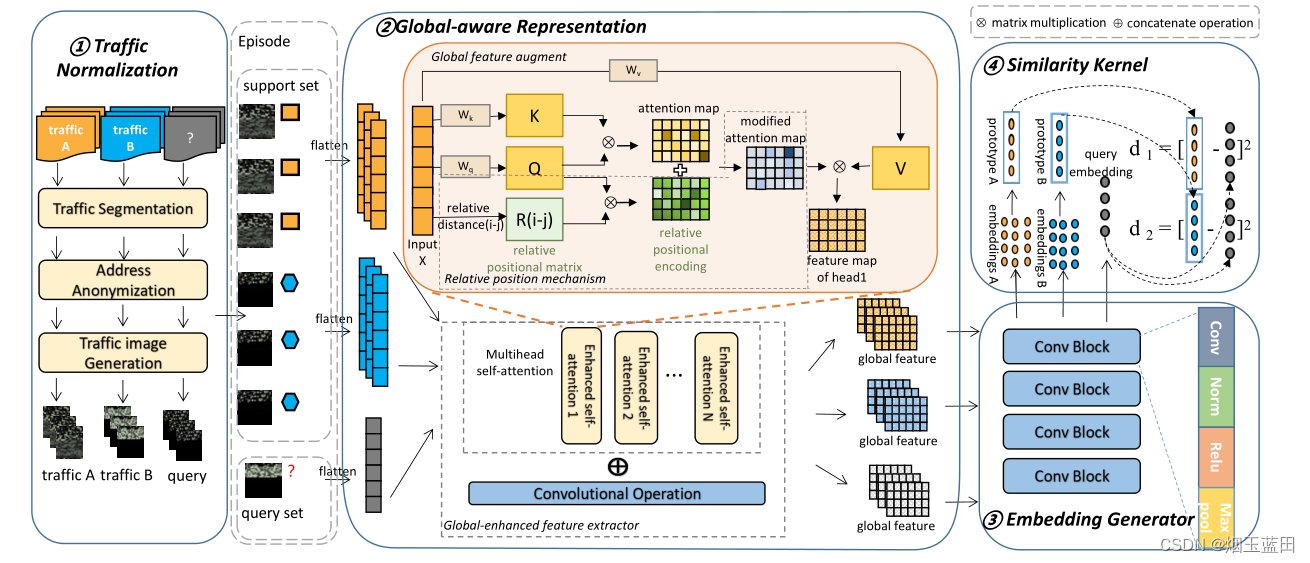
3.2 流量归一化模块
经典三大步:分流、地址匿名、转为图片形式
分流:这里没说是单向流还是双向会话流,使用工具SplitCap
地址匿名:MAC、与IP地址匿名化
转图片:取载荷前784(28*28)字节,超则截,短则填
3.3 全局感知模块(Global-aware representation)
对整个流量输入信息进行聚合,并且引入相对位置机制对字节的位置信息进行建模。
3.3.1 全局信息增强
基于CNN的方法由于卷积核的大小关系,无法捕获有效载荷字节之间远程关系,堆叠CNN后,会造成参数多、存在过拟合的问题,这在少样本的情况下尤为明显。
而注意力机制不会,无视空间距离,考虑每一个载荷之间的相互关系。

对于一个流量图片X,将其拉直,经过运算得到特征向量A:
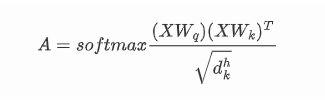
3.3.2 相对位置机制
但是,上式子中,自注意机制是位置不可知的。此属性丢失了字节的位置信息,导致流量表示不全面。于是改进,加入相对位置,A表示如下:
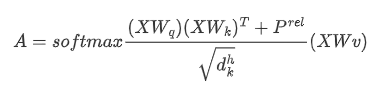
Prel是相对位置矩阵,比如第i与第j个字节的相对位置可以表示如下:
其中qi是字节i 的查询向量,rj-i是字节i和字节j之间的相对位置嵌入。
3.3.3 全局增强的特征提取器(Global-enhanced feature extractor)
通过多头注意力机制后,将不同子空间的特征向量进行拼接,得到MA:
然后这里还和原始图片X做卷积的结果进行再次拼接,得到输出O:
自注意力机制+卷积结果拼接作为输出,考虑了载荷之间的距离信息。
3.4 嵌入生成器
这里是四个相同的卷积块进行堆叠,每个都是3*3的卷积核大小,64通道+BN+ReLu+MaxPooling,得到嵌入向量e:
3.5 相似度核(Similarity Kernel)
每一个查询样本xq转为嵌入向量eq后,与支持集中的每个类型ci进行比较,得出相似度进行分类。ci是每个i类型的样本嵌入向量评价
4、实验
这里抛出三个问题:
小样本学习是否生效
注意力机制与相对位置信息是否必要
GP-Net调参
数据集:USTC-TFC2016
只有一个数据集,个人感觉不够
- 回答问题1:
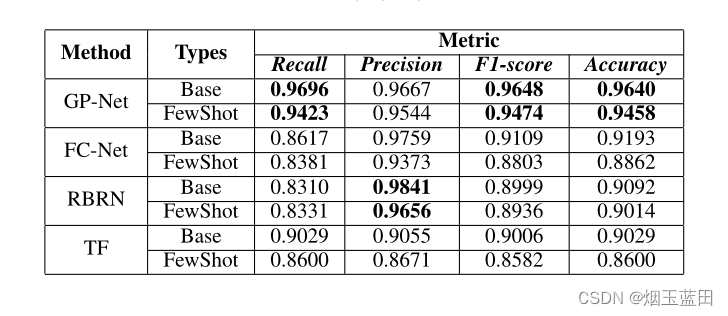
表里的base是在训练查询集的结果,FewShot是在测试查询集的结果。
- 回答问题2:
消融实验表明:
第一行表示没有全局感知模块与相对位置机制的模型
第二行表示没有相对位置机制的模型
但是,我这里感觉在3.3.3 全局感知模块中,加了直接的卷积,没有对那里的卷积进行剔除,感觉这里不好,说不定模型的表现都是基于那个由X直接卷积得到的特征图,而非所谓基于全局感知模块的信息。
- 回答问题3:
调参,不看了
5、总结与思考
- 亮点:少样本学习、元学习
- 模型总体结构: 输入为有效载荷,结构为自注意力(加上相对位置信息)+卷积,而且注意力中并行着卷积,没有做这个的消融实验。