
加密流量分类-论文5:MATEC_A_lightweight_neural_network_for_online_encrypted_traffic
本文于 590 天之前发表,文中内容可能已经过时。
0、摘要
现有的深度学习方法为了获得高精度的分类结果而牺牲了效率,已经不适合大量加密流量的场景,本文提出了一种实现为MATEC的轻量级在线方法,遵循“精简模块重用最大化”的设计原则(Maximizing the reuse of thin modules)。
1、问题引入
老规矩,先说其他方案的缺点:
统计特征+基于机器学习的方法:要获得流量的统计特征,需要观察流的全部或者大部分,内存开销大,只能适用于离线分类。
基于深度学习的方法:为了追求精度,目前提出的神经网络运行时空开销大,效率不够高。
所以本文提出了MATEC的轻量级的神经网络,可以用于在线流分类,输入是流中的随机位置的三个数据包;基本结构:多头注意力机制+一维CNN;期望能提取全局(流级)与局部(包级)的特征,全局特征来自流中信息包之间的交互,而局部特征则包含在一些原始信息包的字节中。
此外,这篇文章的方法通过迁移学习,也对零日应用的流量探测有一定效用。
2、流分类的相关工作(综述部分)
2.1 加密流量分类
分类目标:
基于协议(如HTTP、SSL、SMTP、DNS或QUIC)
基于流量类型(如视频、聊天或浏览)
基于应用程序(如Amazon、Apple、Microsoft或谷歌)
基于网站
分类方法是否在线,可以分为:
在线流量分类(本文提出的是在线方法)
离线流量分类
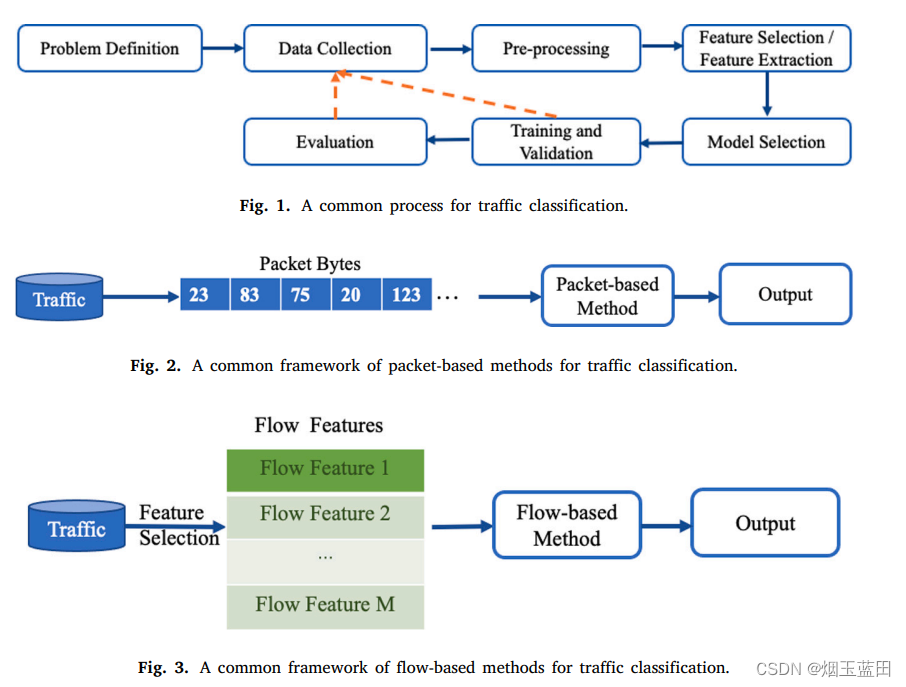
常见流量分类方法,包级(Packet-Based)与流级(Flow-Based),然后介绍了什么是包、什么是流。
流是指所有具有五元组(即传输层协议、源IP、源端口、目的IP、目的端口)相同值的报文,源和目的可以交换。有的论文觉得不能交换,能交换的称作为会话(session)
基于包级(报文级)的分类方法:直接将数据包的字节作为输入,包括报头信息与有效载荷。基于包的方法只关注少数包的详细信息,缺乏对全局特征的关注。(Deep Packet)
基于流级的分类方法:流级特征包括了全局信息。
- 基于机器学习的方法:需要手动设计并且提取统计特征,大部分必须观察整个流或流中的大部分数据包才能获得这些特征,更适合于离线分类。
- 基于深度学习的方法:有使用Bi-GRU对流的字节序列或者流中的包长序列进行特征提取用于分类(FS-Net),有将流中连续的几个报文作为1D-CNN的输入进行分类,有同时使用CNN与RNN分别提取流量的空间特征与时间特征。但是RNN中单元之间的依赖关系使得等待上一个单元的输出非常耗时,本文提出的多头注意力(Multi-head attention)方法就没有这种劣势。
这篇文章的综述特别详尽
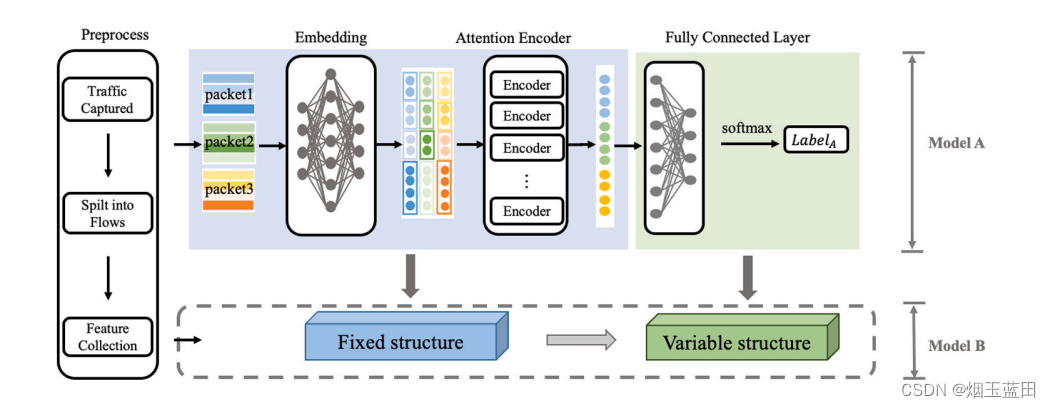
3、模型结构
3.1嵌入层(Embedding)
输入:数据流中的随机位置的连续三个包,既利用了包的统计特征(如包的长度、相对位置)也利用了包的字节特征,对于一个包xi,它的浅层特征向量如下:
每一个分量代表包的一个特征,例如第一个分量可以代表包的相对位置、第二个分量可以代表包长、第三个分量可以代表删除以太网头后的第一个784字节……
嵌入:对于xi中的每一个分量,若其是向量特征,做如下变换,
这样将改向量映射到j维向量,若其是标量特征,则做如下变换
这样,不论是向量特征还是标量特征都会被映射到相同的表示,转换后的向量ei如下:
因此,一个包就转为一个d维向量,一个流转为N*d维矩阵,这里研究N取3,即随机选取流中3个连续数据包的那个3。嵌入向量的位置编码采用绝对编码方式。
3.2 注意力编码层
这里期望注意力编码层能够捕获数据的高维特征,并且捕获到数据包之间的交互关系。这里的注意力层跟Transformer块很像,给出图
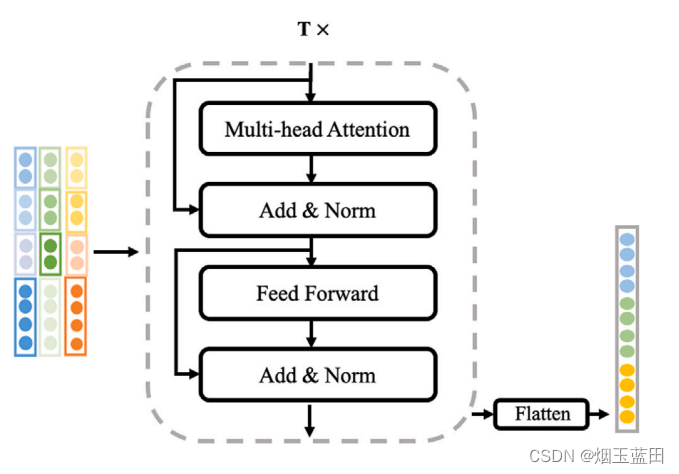
使用注意力机制的好处:
- 并行学习,运算快,参数量少
将数据映射到多个高维度,更能发掘潜在信息
3.3 全连接层
将编码后的特征作为输入,输出为预测标签的概率分布
结构可变,针对不同任务灵活改变全连接层的输出神经元个数,输入的个数是固定的,利用迁移学习优化对新交通数据的微调训练,可以加快模型的收敛速度。
4、总结与思考
- 模型结构声称是第一个将注意力机制引入流量分类任务。
- 通过调整网络结构后端的FC层,可以在新任务上通过少量标签样本进行微调,迅速收敛达到不错的效果。